
Агенти ШІ не виправдали сподівання дослідників

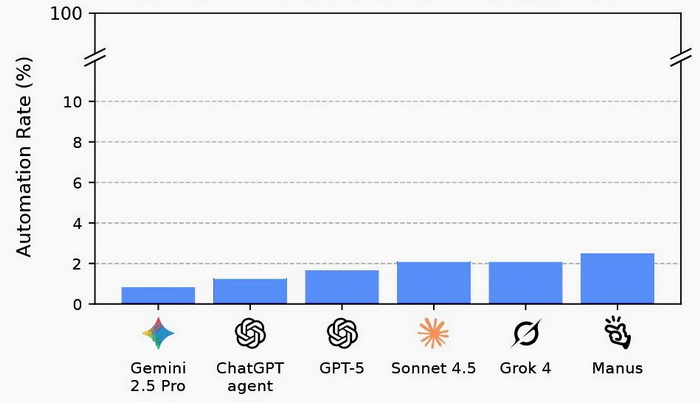
Нове дослідження, опубліковане порталом The Neuron, показало, що сучасні агенти штучного інтелекту все ще майже не готові до виконання реальних робочих завдань. Хоча вже сьогодні компанії очікують, що ШІ-агенти автоматизують будь-які процеси, замінять фрилансерів і самостійно виконуватимуть складні проєкти, та в реальності лише 2–3% завдань виконано успішно.
Тестування під назвою Remote Labor Index, яке провели компанії Scale AI та CAIS, передбачало, що ШІ-агенти намагалися виконувати реальні фриланс-завдання — від написання текстів до дизайну. Найкраща модель заробила 1810 доларів із 143 991 доступного, що становить лише кілька відсотків від потенціалу.
Цей експеримент став холодним душем для галузі, яка вкладає мільярди в ідею повної автоматизації праці. Дослідники перевірили не штучні тести, а реальні оплачувані задачі, що вимагають контексту, творчості та комунікації з клієнтом.
Серед основних труднощів ШІ-агентів називають такі:
- багатоступеневі процеси з неочевидними переходами;
- нечіткі вимоги, які люди уточнюють у процесі;
- завдання, що потребують суджень і контексту;
- робота, яка передбачає ітерації та зворотний зв’язок.
Втім, у виробничих сценаріях добре налаштовані моделі можуть ефективно виконувати повторювані рутинні завдання, а більші — координувати робочі процеси або вирішувати нестандартні випадки. Такі рішення працюють, але залишаються обмеженими та залежать від людського контролю.
Дослідники також наголошують на прихованих витратах: «безкоштовні» агенти мають обмеження швидкості, затримки, перевірки безпеки й потребують ручного доопрацювання.
Водночас 74% компаній, які реально оцінюють ROI від генеративного ШІ, повідомляють про позитивний ефект.



